
人気お笑いコンビ「たりないふたり」のTwitterを分析しました。
この記事のコードでは、次の3つを実施しています。
● 形態素解析のために、不要な記号やフレーズを削除する
● 文章を形態素(品詞)に分解し、語句の出現回数をカウントする
● 出現回数の多い語句とその出現回数を、グラフに表示する
コードの解説は基礎集計と自然言語処理の2つのパートに分かれており、基礎集計編はこちらになります。
また、結果を詳しく知りたい場合は、こちらのリンクから確認ください。
はじめに
たりないふたりとは、2人のお笑い芸人南海キャンディーズの山里亮太とオードリーの若林正恭による期間限定のお笑いコンビです。
2012年から不定期で活動し、2021年5月31日にコンビを解散しました。
コード
インポート
今回のコードを動かすのに不要なライブラリもインポートしています。
import tweepy
import numpy as np
import pandas as pd
import re
import datetime
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sb
from IPython.display import display
mpl.rcParams['font.family'] = "IPAexGothic"
plt.rcParams["font.size"] = 18
pd.set_option("display.max_colwidth", 280)
import MeCab形態素解析のために、不要なフレーズを削除する
def delete_tweet_person(name_list, df, col_name='TW_TEXT'):
# 自然言語処理の前処理で、呟き主を示す言葉をテキストから削除する
re_person = re.compile("|".join(name_list))
df[col_name] = df[col_name].apply(lambda x:re_person.sub("",x) )
def redundant_phrase_deleted(df, col_name='TW_TEXT'):
'''
自然言語処理の前処理として、自然言語処理に不要な記号を削除する。
'''
re_half = re.compile(r'[!-~]') # 半角記号,数字,英字
re_full = re.compile(r'[︰-@]') # 全角記号
re_full2 = re.compile(r'[、・’〜:<>_|「」{}【】『』〈〉“”○〔〕…――――◇~・]') # 全角で取り除けなかったやつ
re_comma = re.compile(r'[。]') # 読点のみ
re_url = re.compile(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+')
re_tag = re.compile(r"<[^>]*?>") #HTMLタグ
re_n = re.compile(r'\n') # 改行文字
for comp in [re_half, re_full, re_full2, re_comma, re_url, re_tag, re_n]:
df[col_name] = df[col_name].apply(lambda x: comp.sub("",x) )
w_list = ['文責若林', '文責悪鼠', '歌責若林', 'MASA', '文責・若林', '文責若','文責カレーライス']
y_list = ['文責山里', '山里亮太', '文責福神漬け']
b_list = ['文責山里若林', '文責山里・若林']
p_list = w_list + y_list + b_list
delete_tweet_person(name_list, df_text_mod, col_name='TW_TEXT')
redundant_phrase_deleted(df_text_mod, col_name='TW_TEXT')文章を形態素(品詞)に分解し、語句の出現回数をグラフで表示する
def word_count_from_text(text,
word_dict,
exclude_word_list=[],
collect_pos = ['固有名詞', '一般', 'サ変接続', '形容動詞語幹']):
'''
テキストを品詞分解し、collect_posで定めた品詞、かつ、exclude_word_listに含まれていない単語を辞書に格納する関数
※ 品詞は、Macab独自の名称が使われている
参考URL:https://so-zou.jp/software/tech/linguistics/language-processing/morpheme/mecab/pos-id-def.htm
'''
node = mecab.parseToNode(text)
while node:
# Get word
word = node.surface
# Get pos
pos = node.feature.split(",")[1]
if (pos in collect_pos)&(word not in exclude_word_list):
word_dict[word]= word_dict.get(word, 0) + 1
# Move to next word
node = node.next
return word_dict
def create_word_dict(df, exclude_word_list=[], collect_pos = ['固有名詞', '一般', 'サ変接続', '形容動詞語幹']):
'''
word_count_from_text()関数を、dfで使用するための関数
本当はfor文を使用したくなかったが、技術不足により、やむを得ず使用した
'''
word_dict={}
#Mecabでの形態素解析のタイプを選択
mecab = MeCab.Tagger ('-r C:\progra~2\MeCab\etc\mecabrc-u')
for i in range(df.shape[0]):
text = df.loc[i, 'TW_TEXT']
word_dict = word_count_from_text(text, word_dict,
exclude_word_list=exclude_word_list,
collect_pos = collect_pos)
return word_dict
def show_word_count_graph(word_dict, g_title='twitterで多く使用している単語トップ10'):
'''
word_dictをグラフ表示するための関数
'''
#グラフ表示のために、dictをdfへ変換する
df_graph =pd.DataFrame(word_dict.items(), columns=['word','count'])
df_graph =df_graph.sort_values('count', ascending=False).head(10)
#display(df_graph)
#グラフを表示する
plt.figure(figsize = [8,6])
base_color = sb.color_palette()[0]
sb.barplot(data = df_graph, y = 'word', x = 'count', color=base_color)
plt.title(g_title)
plt.xlabel('使用回数')
plt.ylabel('使用単語');
#各タームごとに、頻出語句を表示する
for col_word in df_text_mod['term'].unique():
df_temp = df_text_mod.copy()
#つぶやき主が判断できないツイートを削除する
df_temp = df_temp[(df_temp['PERSON']=='若林')|(df_temp['PERSON']=='山里')]
df_temp = df_temp[df_temp['term']==col_word].reset_index() #create_word_dict()関数でlocを使用するので、かならずreset_index()をする
word_dict = create_word_dict(df_temp,
exclude_word_list = ['「','」','♪'], #不要な記号が頻出語句として表示されたので、事前に削除する
collect_pos=['形容動詞語幹','ナイ形容詞語幹','サ変接続'] #結果に応じて品詞を調整する
)
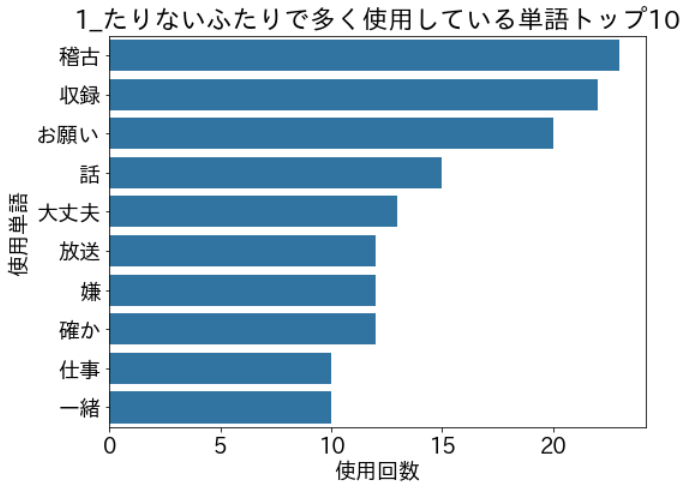
title = col_word + 'で多く使用している単語トップ10'
show_word_count_graph(word_dict,g_title=title)Mecabで形態素に分割する際には、こちらの記事を参考にさせてもらい、mecab-ipadic-neologdの辞書を使用しました。
このコードを実行すると、以下のように結果が表示されます。
関連記事
コードの解説は基礎集計と自然言語処理の2つのパートに分かれており、基礎集計編はこちらになります。
また、結果を詳しく知りたい場合は、こちらのリンクから確認ください。


コメント