こむぎパパは、いちおうデータ分析の仕事をしているのですが、
■ 新しい技術を使って、なんかしてみたいな~
■ そうだ!コーギー関連のTwitterのつぶやきを可視化してみよう!
と思い立ったので、さっそく実行してみました。
なお、こむぎパパは西東京に住んでいて、コーギーのこむぎを飼っています。
結果
7月7日~7月13日のツイートから単語を抽出しています。
また、文字が大きい単語が、ツイートの中でより多く使用されています。
コーギー関連のつぶやきを可視化
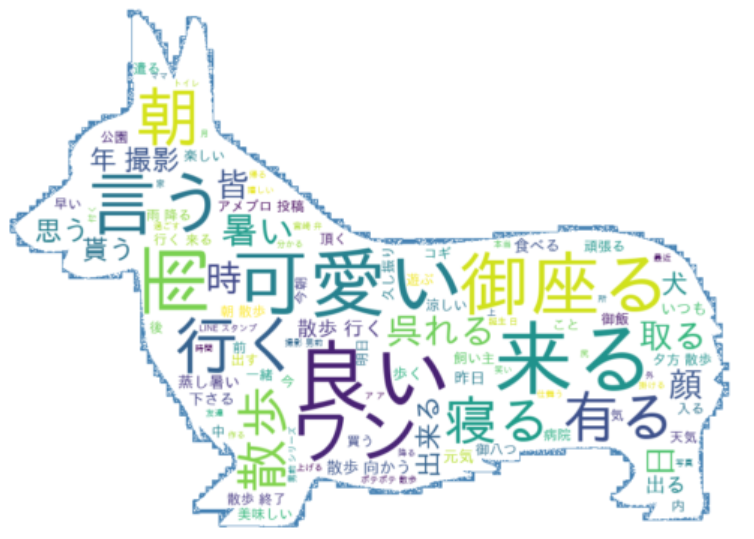
こむぎ
やっぱり、飼い主はコーギーを可愛いって思ってるのね!
コーギーと雷に関連するつぶやきを可視化
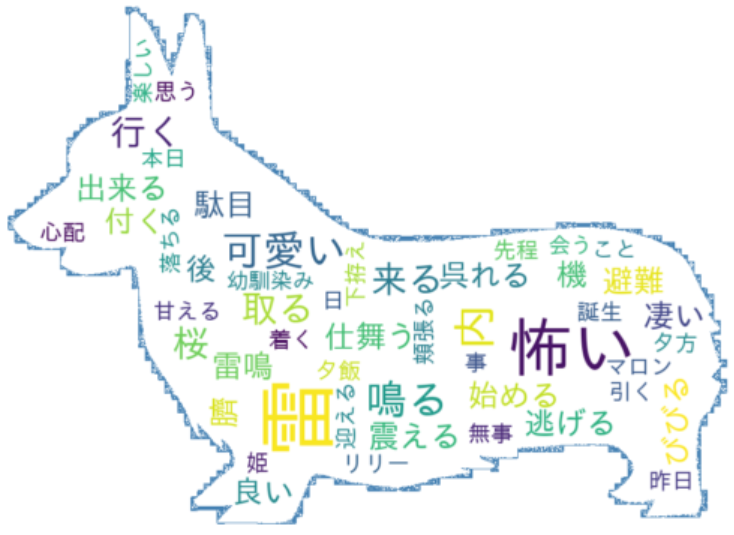
こむぎ
雷は怖いわよね~
フレンチブルドッグ関連のつぶやきを可視化

こむぎ
コーギーじゃなくても、愛犬は可愛いわよね~
柴犬関連のつぶやきを可視化

こむぎ
柴犬の場合、「クイズ」とか「参加」が上位にきてるわ。
何かあったのかしら?
こむぎパパ
どうやら、柴犬が回答のクイズが出題されたようだぞ!
7月12日(月)Qさま視聴者参加クイズ 第1問! 1位は #柴犬 と解答!結果発表は放送で発表しますので 是非ご確認ください!
— ひろ (@pipiron) July 12, 2021
コード
コードは以下の通りです。
4つのブロックに分けてQiitaで解説してますので、気になる場合はQiitaもご確認ください。
- TwitterAPIの上限までTweetを取得する|つぶやきをWordcloudで可視化①
- ツイートを整形する【🐶のような絵文字も削除】|つぶやきをWordcloudで可視化②
- SudachiPyで形態素単位に分割|つぶやきをWordcloudで可視化③
- WordCloudで可視化|つぶやきをWordcloudで可視化④
import tweepy
import pandas as pd
import datetime
# Setting 280 characters in a column
pd.set_option("display.max_colwidth", 280)
import emoji
from sudachipy import tokenizer
from sudachipy import dictionary
import numpy as np
from wordcloud import WordCloud
from PIL import Image
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.family'] = "IPAexGothic"
def get_api_value(consumer_key,consumer_secret,access_token,access_secret):
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
return api
def collect_tweet_data(q, api):
'''
ツイッターAPIを使用してデータを収集し、リストを作成する関数
15分で180リクエストという制限があるため、175リクエストで17500ツイートを取得するよう指定
'''
tweet_data = []
for tweet in tweepy.Cursor(api.search_tweets, q=q, result_type='recent', count=100).items(18000):
# twitterAPIの仕様で7日前までのツイートしか取得できなく、最後まで取得すると、
# 取得したtweetのIDとmin_id_numが等しくなる
tweet_data.append([tweet.id_str,
tweet.user.screen_name,
tweet.created_at+datetime.timedelta(hours=9),
tweet.text.replace('\n',''),
tweet.favorite_count,tweet.retweet_count])
return tweet_data
def create_tweets_df(q,api):
tweet_data = collect_tweet_data(q=q,api=api)
# 取得する列名を指定する
columns_name=["TW_NO","USER_NAME","TW_TIME","TW_TEXT","FAV","RT"]
df=pd.DataFrame(tweet_data,columns=columns_name)
return df
def remove_emoji(text):
return emoji.get_emoji_regexp().sub(u'', text)
def format_df_text(text_col,df):
'''
ツイートから不要な情報を削除
(形態素解析でsudachiを使用予定のため、textの修正が少ない)
'''
df['temp'] = df[text_col].replace(r'https?://[w/:%#$&?()~.=+-…]+', '', regex=True) #画像へのリンクを削除
df['temp'] = df['temp'].replace(r'@[w/:%#$&?()~.=+-…]+', '', regex=True) #'@'によるメンションを削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(半角)を削除
df['temp'] = df['temp'].replace(r'#(\w+)', '', regex=True) #ハッシュタグ(全角)を削除
df['temp'] = df['temp'].apply(lambda x: remove_emoji(x)) #🐶のような絵文字を削除
return df['temp']
class SudachiTokenizer():
def __init__(self, dict_type="core", mode="C", stopwords=None, include_pos=None):
if dict_type not in ["core", "small", "full"]:
raise Exception("invalid dict_type. 'core' ,'small' or 'full'")
self.tokenizer_obj = dictionary.Dictionary(dict_type=dict_type).create()
if mode not in ["A", "B", "C"]:
raise Exception("invalid mode. 'A' ,'B' or 'C'")
self.mode = getattr(tokenizer.Tokenizer.SplitMode, mode)
print(self.mode )
if stopwords is None:
self.stopwords = []
else:
self.stopwords = stopwords
if include_pos is None:
self.include_pos = ["名詞", "動詞", "形容詞"]
else:
self.include_pos = include_pos
def parser(self, text):
return self.tokenizer_obj.tokenize(text, self.mode)
def tokenize(self, text, pos=False):
res = []
for m in self.parser(text):
p = m.part_of_speech()
base = m.normalized_form() #.dictionary_form()
#print(base, ": ", p)
if p[0] in self.include_pos and base not in self.stopwords and p[1] != "数詞":
if pos:
res.append((base, p[0]))
else:
res.append(base)
return res
def create_word_chain(col, df, tokenizer):
word_lists=[]
for i in range(len(df)):
text = df.loc[i, col]
word_list = tokenizer.tokenize(text, pos=False)
for word in word_list:
word_lists.append(word)
word_chain =' '.join(word_lists)
return word_chain
def show_wordcloud(word_chain, msk, font_path='ipaexg.ttf', mx_words=100):
#WordCloudの指定
wc = WordCloud(background_color="white",
font_path=font_path, max_words=mx_words, mask=msk,
max_font_size=100, contour_width=1, contour_color='steelblue')
wc.generate(word_chain)
#wordcloudの描写
plt.figure(figsize=(12,10))
plt.imshow(wc, cmap=plt.cm.gray, interpolation="bilinear")
plt.axis("off")
plt.show()
# Getting customer key and access token
# 自身で取得した値を代入ください
consumer_key = 'xxxxxxxxxxxx'
consumer_secret = 'xxxxxxxxxxxxxxxx'
access_token = 'xxxxxxxxxxxxxxx'
access_secret = 'xxxxxxxxxxxxxxxxxxxxx'
api=get_api_value(consumer_key,consumer_secret,access_token,access_secret)
q = f"#コーギー exclude:retweets -filter:replies"
df = create_tweets_df(q, api)
df['TW_TEXT_mod'] = format_df_text('TW_TEXT',df)
include_pos = ["名詞", "動詞", "形容詞"]
stopwords = ["コーギー", "見る","為る", "今日","無い","居る","成る"]
sudachi_tokenizer = SudachiTokenizer(dict_type="core", mode="A", stopwords=stopwords, include_pos=include_pos)
word_chain = create_word_chain('TW_TEXT_mod', df)
msk = np.array(Image.open("corgi.jpg"))
show_wordcloud(word_chain, msk)
コメント